SM Ninja
Project Overview
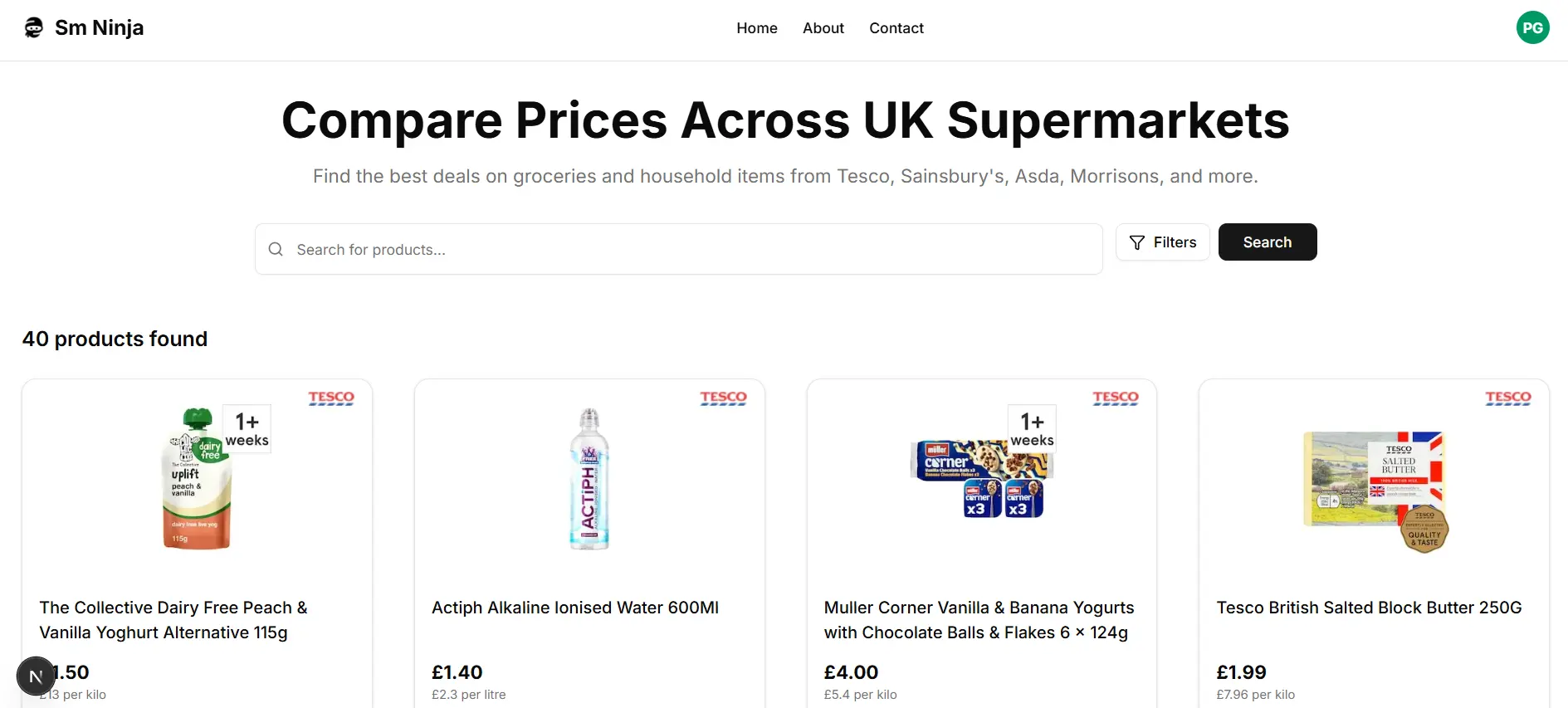
SMNinja (Supermarket Ninja) is a comprehensive price comparison platform that helps users find the best deals on grocery products across major UK supermarkets. The application combines a Next.js frontend with a Python web scraping backend to deliver real-time price comparisons and shopping recommendations.
The project consists of two main components: a web scraping system built with Python that collects product data from various supermarkets, and a user-facing web application built with Next.js, TypeScript, and Prisma that presents this data in an intuitive interface.
Technical Highlights
Scraping
Personalised scraping programs (ninjas) retreive updated information from the supermarkets' webs.
Secure Authentication
OAuth integration with secure credentials and secure session management using Prisma adapter.
Prisma ORM
Type-safe database operations with Prisma for efficient data management.
Technical Implementation
SM Ninja leverages the T3 stack to create a robust and type-safe application. Here's a breakdown of the key technical aspects:
- Next.js: Provides server-side rendering, API routes, and optimized performance for a seamless user experience.
- TypeScript: Ensures type safety throughout the application, reducing runtime errors and improving developer experience.
- Prisma: Offers a type-safe database client for efficient data modeling and querying, simplifying database operations.
- OAuth Authentication: Implements secure user authentication with multiple providers (Google, GitHub) using the Prisma adapter.
- Tailwind CSS: Provides utility-first styling for a responsive and consistent UI across all devices.
Web Scraping System
The backbone of SMNinja is its web scraping system, built with Python. This system regularly collects product data from major UK supermarkets:
- Data Collection: Uses BeautifulSoup and requests libraries to extract product information from supermarket websites.
- Anti-blocking Measures: Implements robust headers and user agent rotation to avoid being blocked by target websites.
- Scheduled Scraping: Runs daily to update prices, only updates old data to avoid overloading the database.
- Error Handling: Robust error handling and retry mechanisms to deal with website changes and temporary failures.
Lessons Learned
MediConnect was my first project using the T3 stack, and it provided valuable learning experiences:
- T3 Stack Benefits: I gained a deep appreciation for the type safety and developer experience provided by the T3 stack. The combination of Next.js, TypeScript, and Prisma significantly reduced runtime errors and improved code quality.
- Database Design Importance: I learned the importance of careful database schema design, especially for applications with complex relationships like patient-doctor connections and appointment scheduling.
- Web Scraping Ethics and Limitations: I learned to balance the need for data with respecting website terms of service and server load. Implementing proper request throttling, caching, and following robots.txt guidelines was essential.
- User-Centered Design: The project reinforced the importance of focusing on user needs when designing features. The most valuable aspects of the application were those that directly helped users save money on their regular shopping.

